説明
graphics::hist()は指定されたデータを元に頻度表を計算するジェネリック関数である。
通常の使用法
とにかく頻度表を作成するには、以下のように記述すればよい。
hist(頻度表を作成するデータのベクトル)
頻度表の定義や描画方法をカスタマイズするには引数を適宜設定する。
詳細な使用法
## Default S3 method:
hist(x, breaks = "Sturges",
freq = NULL, probability = !freq,
include.lowest = TRUE, right = TRUE,
density = NULL, angle = 45, col = NULL, border = NULL,
main = paste("Histogram of" , xname),
xlim = range(breaks), ylim = NULL,
xlab = xname, ylab,
axes = TRUE, plot = TRUE, labels = FALSE,
nclass = NULL, warn.unused = TRUE, ...)引数
頻用されるものを説明する。
breaks
ヒストグラムのセルの作成方法を指定する。ここでいうセルとは、階級、binなどと同義である。
実際には以下のいずれかを与える。
- セル間のブレイクポイントを指定するベクトル
- ブレイクポイントのベクトルを計算する関数
- セル数を指定する単一の数値
- セル数を計算するアルゴリズムを指定する文字列
- セル数を計算するための関数
後半3つの場合には、セル数はサジェスチョンに留まる。ブレイクポイントはきれいな値(pretty values)に設定される。breaksが関数の場合には、xベクトルがその関数の唯一の引数として引き渡される。
一般にヒストグラムにおいてはセルの設定が重要である(設定次第で同じデータに対するヒストグラムでも視覚的印象が全く異なるものができる)。例えばセルの数を無限に増やしていけば、ヒストグラムは事実上ストリップチャートになってしまう。ヒストグラムのセルを決定する決定的な方法はないが、スタージェスの公式など頻用されるアルゴリズムが存在する。
freq
論理値。TRUEの場合、ヒストグラムは頻度(個数そのもの)が描画される。FALSEの場合、確率密度(全体を1とした時の相対頻度)が描画される。デフォルトはTRUEである(ブレイクが等間隔(かつかprobability引数が指定されていない限り)。実際にはY軸に表示される数値が異なるだけであり、グラフの形状は同じである。
main
ヒストグラムのタイトル文字列を指定する。何も指定しないと”Histogram of データ名”というタイトルが自動で表示される。何も表示したくない場合は、main=””と明示する必要がある。
xlim, ylim
描画されるヒストグラムのx軸(xlim)、y軸(ylim)の値の範囲を指定する。実際の指定はxlim=c(下限値、上限値)の形式でベクトルを使用して行う。
xlimはヒストグラムの描画に使用されるだけであり、ヒストグラムそのものの定義(=階級の定義)には使用されない。階級の定義は引数 “breaks” によって行われる。
返り値
“histogram”クラスのオブジェクトである。”histogram”クラスbreaks, counts, density, mids, xname, equidistの要素を持つ。print()で内容を出力可能。
使用例
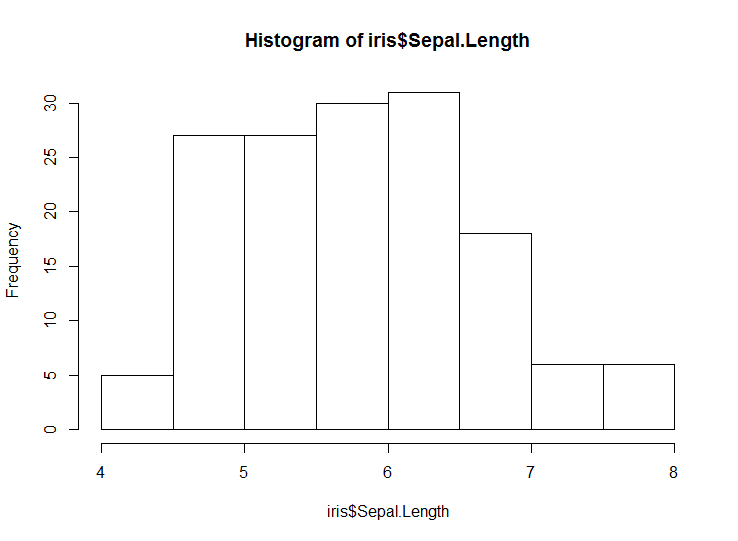
> data(iris) > print(hist(iris$Sepal.Length)) $breaks [1] 4.0 4.5 5.0 5.5 6.0 6.5 7.0 7.5 8.0 $counts [1] 5 27 27 30 31 18 6 6 $density [1] 0.06666667 0.36000000 0.36000000 0.40000000 0.41333333 [6] 0.24000000 0.08000000 0.08000000 $mids [1] 4.25 4.75 5.25 5.75 6.25 6.75 7.25 7.75 $xname [1] "iris$Sepal.Length" $equidist [1] TRUE attr(,"class") [1] "histogram"


コメント